


Evolving Intelligent Systems
Human-Inspired Evolving Machines – The Next Generation of Evolving Intelligent Systems?
Edwin Lughofer
Abstract: In today's real-world applications, there is an increasing need to integrate new information and knowledge into model-building processes to account for changing system dynamics, new operating conditions or environmental influences. This is essential to increase the efficiency of models in terms of performance and process safety during on-line operation and production phases. Evolving Intelligent Systems (EIS) [1] constitute a powerful methodology to address this need, integrating mechanism for continuous adaptation of parameters, expansion of model structures, on-the-fly memory extension of system models and real-time modeling. The current situation in EIS is that system knowledge builds largely upon data (usually measurements, features extracted from the process). There is little active intervention by experts and/or operators working with the systems. Interaction is generally confined to passive supervision or – at most - in form of good/bad rewards on model decisions.
This briefing article discusses requirements, possible methods and key components to enhance communication by dynamically integrating the previous system experiences from human beings into evolving models (human feedback integration component). Model interpretability and understandability are important topics to motivate users to provide enhanced feedback (model interpretation component). Finally, the complete concept will lead to an enriched human-model interaction scenario, termed human-inspired evolving machines, which might serve as a cornerstone for the next generation of evolving intelligent systems.
Index Terms: human-inspired evolving machines, enriched human-model interaction and understandability of evolved models.
1. Introduction
1.1. Background
In modern industrial systems, automatic construction of models from process data (data-driven models) using soft computing, machine learning and data mining methods is becoming increasingly attractive, because the complexity of these systems is growing continuously. Deducing analytical (white box, first principle) models from physical, chemical, biological etc. laws may require long development times or is, in some cases, simply impossible due to ensnared environmental influences, imperfectly understood natural phenomena and dependencies within a system. A major advantage of data-driven models over first principle models, is the generic applicability of their training phases: in fact, data-driven models can be built generically without knowing any underlying physical, chemical or biological laws. Process data available as measurements, context-based (e.g. features extracted from image objects) or structured data (e.g. descriptive data from database entries), is fed into model learning and evaluation algorithms, which aim to optimize the expected prediction error (empirical risk) of the models without using any external background information. The final model represents a mapping of input variables to the target concept.
In the case of strongly varying system dynamics caused by changing operating conditions or dynamic or unexpected environmental influences, the conventional data-driven model design generally does not cover all possible system states or reflect all system variations because training data is usually collected from the most typical scenarios. This means that significant extrapolation during on-line prediction may arise, which makes the model responses quite unreliable. In other cases, data may be so time-intensive to collect or annotate (e.g. labeling in classification scenarios), that an initial model can only be built from a handful of data. Thus, the models need to be updated and expanded dynamically. Ideally, this is performed on-the-fly based on new incoming data that is collected continuously during the on-line process of the systems (also called data streams), thereby avoiding time intensive re-training phases and guaranteeing models with high flexibility and rapid updating.
1.2.Evolving Intelligent Systems (EIS) – State of the Art
In the last decade, various methodologies have been developed which are capable of addressing the issues mentioned above. Some of these are summarized under the umbrella of evolving intelligent systems [1]. They include methodologies that continuously adapt parameters, expand model structures, extend the memory of system models on-the-fly, allow real-time modeling by integrating concepts from the field of incremental learning, and thus prevent time intensive re-training phases. Depending on the model architecture used, different forms of evolving models have emerged: evolving fuzzy systems [2], evolving rule-based models [3], evolving connectionist systems [4] as specific variants of neuro-fuzzy systems, evolving neural networks [5] and evolving hybrid systems (supporting combinations of data-driven architectures) [6]. They all rely on concepts and architectures used in the soft computing community and can handle classification and system identification as well as regression/approximation problems. In the field of machine learning, a parallel line of research already emerged in the nineties, which was significantly further investigated and fully developed during the last decade: (incremental) learning from data streams --- see [7] for a recent monograph which summarizes the most important concepts, including incremental tree learners (Hoeffding trees [8]), incremental Naïve Bayesian methods, on-line Oza bagging and boosting [9] and algorithms for handling drifts in data streams appropriately. Most of these are implemented in the MOA (Massive Online Analysis) framework [10], which is able to process huge data streams incrementally. Incremental SVMs, as conceived by Diehl and Cauwenberghs [11], achieve adiabatic updates meaning that the same solution of support vectors is found as with all the training samples used at once in batch mode. Incremental variants that combine an ensemble of classification models with adiabatic updates were presented in [12]. A semi-supervised learning approach in connection with k-nearest neighbors was described in [13].
In the field of data mining and pattern recognition, incremental and evolving techniques can be found in connection with various clustering algorithms, such as eClustering [14], evolving vector quantization (eVQ) [15], recursive Gustafson-Kessel clustering [16], single-pass k-means [17] and fuzzy c-means [18], and the approach reported in [19]. A field of research within adaptive pattern recognition that is related to incremental clustering is the concept of dynamic data mining [20], which also takes the spatial information of data into account, i.e. cluster models are updated on the basis of data (blocks) coming from different data sources. The concept applies a collaborative optimization scheme [21], taking explicit advantage of evolving the models block-wise. For a more comprehensive and detailed survey on EIS methods, see the previous article by P. Angelov.
In all of these methodologies, three concepts play a major role: 1.) incrementality, 2.) single-pass learning and 3.) stability/robustness of the learning process which includes convergence to batch solutions with recursive or adiabatic updates. Possibilities for how to tackle stability/robustness is for instance handled and analyzed in detail in [22], [23] and [24]. Single-pass incremental learning means that a single sample is sent into the model update and then immediately discarded, so no previous (blocks of) data are used; this is performed in incremental learning steps. Thus, the methodologies are applicable to a wide range of real-world applications, where fast model updates are essential in order to react appropriately to dynamic process changes. Examples are on-line quality control, visual inspection of manufactured items, stock market forecasting, eSensors (soft sensors with adaptation capability), adaptive control, tracking of objects in video streams and adaptive knowledge discovery in bioinformatics. Another large field of application is modeling in the context of very large data-bases (VLDB), which cannot be loaded all at once into the virtual memory of a computer. Here, the only possibility to obtain models is incremental processing by successively loading data samples/blocks from the data base. Due to their ability to extend memory continuously by learning from dynamically changing environments, EIS can also be seen as a contribution to the field of artificial intelligence community.
1.3.The Next Generation EIS – Outline
All of the aforementioned EIS approaches have one common characteristics: they employ models which are completely extracted from data sources (usually processed as streams, on-line measurements) in evolving and incremental learning steps over time and space.
Very little attention is paid to integrating the long-term experience and knowledge of experts working with these systems into the evolved models in order to enrich their memory and sharpen their perspective.
Current methodologies are restricted to integrating some positive/negative rewards of operators on model decisions; for instance see [25], where image classifiers are evolved on the basis of human feedback; or [26], where operators are required to provide feedback to an email spam filtering model. In fact, in the case of classification tasks such rewards/responses are mandatory in order to be able to improve the decision models, as the ground truth class labels upon which classifiers can be updated are rarely automatically available. Active [27] and semi-supervised learning strategies [28] may help to reduce the annotation efforts of operators when providing feedback in on-line classification tasks. Furthermore, an operator’s behavior may change over time, which requires an evolving agent’s behavior approach when classifying on-line data streams [29].
Often, the models and their outputs are supervised passively for monitoring and quality control tasks: in the case of atypical model behaviors, the operators intervene, for instance, by correcting some system setups or by switching off some components.
This article examines first concepts and components for an enriched human-model communication scenario, where objective data and subjective experience/knowledge can be combined in one homogenous (on-line) model building --- we call this concept human inspired evolving machines(HIEM), as systems/models are evolved by means of machines, but with the help of human interaction, intervention and inspiration. These should lay a methodological foundation for early quality enhancement and process safety in evolving models; for instance, consider extreme situations of which the operators are aware, but which have not been “seen” by the system and the data-generating process, and are hence not reflected in the data collected so far.
Specific EIS types form an ideal basis for enriched interaction, because they are able to integrate new information step-wise in a life-long learning context and without any re-training/re-setting phases (in fact, either re-training based on data or re-setting based on expert knowledge would cause one knowledge source to displace the information by the other).
The next section discusses the HIEM concept and its requirement in more detail, shows its central framework and provides a summary of its most important components. Section III provides a discussion of the requirements of the architecture used in the EIS concept to encourage experts and operators towards enriched communication with the evolved intelligent systems. Section IV explores possible methodologies for integrating and assimilating human knowledge into current state-of-the-art EIS.
2. BASIC CONCEPT OF HUMAN INSPIRED EVOLVING MACHINES (HIEM)
2.1.General Considerations
Pedagogical research shows that engagement and learning achievement increase when learners and teachers participate in a dialogue rather than one-way communication.
Thus, the basic aim of the HIEM concept is to develop evolving machine learning components which are able to go beyond conventional EIS by combining different information sources, objective data and subjective experience, such that both, human and machine learning model benefit from each other. By coordinating their interpretations and actions, a human-computer partnership will leverage the best skills of each. This may also significantly reduce training time and increase industrial confidence in adaptive, evolving systems at an earlier stage.
A key role for designing such components lies in a deeper, evidence-based understanding of how people might interact with machine learning systems in various contexts. In this regard, important questions will be:
- What are the elements that constrain the level and nature of feedback?
- How can environmental and process related information be incorporated to augment user input?
- How can levels of confidence, and of engagement with the system be measured?
- How can the interactions be made intuitive from the user’s perspective?
The answer to these questions will serve as cognitive stimulation and motivate users to interact with systems on higher level. Users contribute their knowledge (from past experience) in order to modify structural components of the models manually —for instance, by inputting rules, by directly manipulating the decision model boundaries, or by requesting data items/synthesized exemplars in certain regions. The latter can be seen as a form of human-based design of experiments (DoE), which contrasts with model-based DoE [30], in which the model itself suggests regions for exemplar creation based on reliability and uncertainty concepts.
2.2.The HIEM Framework
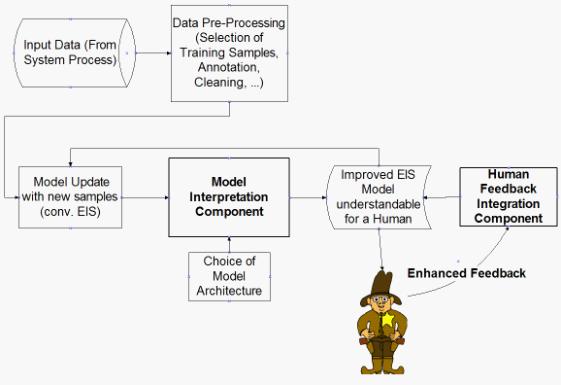
Figure 1: The Human-Inspired Evolving Machines (HIEM) Framework
Figure 1 shows a diagram of the HIEM framework.
The left part consists of conventional data pre-processing and evolving modeling components. The bolded components are those which might support human engagement for enriched interaction and address the questions raised above:
- The model interpretation component (MIC) which seeks to liberate EIS models from black box behavior.
- The human feedback integration component (HFIC) which is responsible for the correct interpretation and integration of human input into the EIS model.
In the subsequent two sections (Sections III and IV), some basic ideas, important considerations and first concepts that may serve as useful inspirations and corner stones when designing these components are provided.
3.Model Interpretation Component (MIC)
The basic aim of the model interpretation component is to prepare evolving models in a way that their appearance is –at least to some extent – human interpretable and understandable. This is absolutely necessary to keep the level of users’ engagement high. Currently, the majority of EIS approaches rely on precise modeling tasks, that is, they try to approximate the relations, dependencies and input-output mappings implicitly contained in the systems as accurately as possible. In doing so, they mostly deliver black box models with little or no potential for gaining insights into the process, thereby inhibiting a deeper understanding of present and prevailing coherences and connectivities and finally how the system really works. Thus, an enriched communication where the user contributes knowledge to the model building process (complex precise evolving models), is currently very unlikely and in some cases (e.g. evolving neural networks) impossible.
Based on these considerations, it is obvious that a model interpretation component must integrate two important components:
- An appropriate model architecture applied in the training process
- Methods for improved model transparency, readability and interpretability
3.1.Choice of Model Architecture
The first issue is defining architectures which support per se any form of interpretation and therefore enable enhanced communication with the user. This makes neural networks, support vector machines and various forms of evolutionary algorithms less attractive than any form of rule-based models such as decision trees, patterns trees and fuzzy systems. Decision trees can be represented in rule form (one path from the root to a terminal node can be read as one rule [29]), and are thus a powerful means (also used in ML model visualization components, e.g. [32]). However, their incremental learning capabilities are somewhat restricted, in order to guarantee a reasonable accuracy, sub-trees and leaves must be re-structured and traversed repeatedly, when they are fed new samples [33]. Furthermore, they do not allow any vague statements and confidence levels in their decisions, which often results in an overly “black and white” interpretation of a model’s decision. Fuzzy systems offer linguistically readable rules in IF-THEN form and also allow uncertainty feedback in the model decision through the concept of conflict and ignorance, which they can resolve in natural way [34]. The inherent fuzziness in their rules allows their knowledge to be expressed in form of vague statements using linguistic terms, which may accord with users experience. The Takagi-Sugeno-Kang family of fuzzy systems is able to provide a reasonable tradeoff between readability and accuracy. In fact, these systems are known to be universal approximators, that, at the same time, offer insights in the form of local model trends and linguistic rule premise parts [35]. The major disadvantage of conventional fuzzy systems is their flat model architecture: each input feature/variable is present in one premise part of each rule, often causing an unnecessary overload of rule conditions. Promising alternative architectures are fuzzy pattern trees [36] and fuzzy decision trees [37] which both combine the favorable aspect of a hierarchical model structure with the concepts of fuzziness and uncertainty. The authors of [37] presented a first attempt for evolving fuzzy decision trees by growing leaf nodes on demand, fuzzy pattern trees can be trained incrementally as demonstrated in [38].
Figure 2 shows an example of a flat Mamdani fuzzy model and of a hierarchical fuzzy decision tree omitting some complexity along the right branch (one rule less). “Area < C1” can be seen as equivalent to “Area is LOW”, where LOW denotes the fuzzy set in the lower region of the range of ‘Area’ and which has ½ overlap with HIGH at C1.
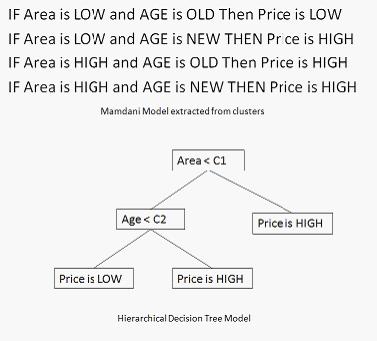
Figure 2: Flat Mamdani fuzzy model and equivalent hierarchical fuzzy decision tree model
Alternatively, instance-based learners (often referred to as lazy learners [39]) may be used instead of model-based learners. In specific situations, this type of learner may offer another viewpoint of interpretability: for instance, a user may asky why a machine vision (image) classifier made a particular decision: in the case of an instance-based learner such as the k-nearest neighbors approach, the answer would be simply to show the user the annotated reference image exemplars that are closest to the current sample. On the other hand, instance-based models constantly build new local models, which makes a deeper analysis of model behavior (structures, parameters) over time almost impossible and inhibits compact knowledge gain of system characteristics in one joint global model. For a detailed discussion of instance-based versus model-based learners, refer to the subsequent article by E. Hüllermeier.
3.2. Interpretability Improvement Concepts
Although a careful choice of model architecture may support interpretability, models adaptively trained and evolved from on-line data streams are usually relatively complex and still bear very little interpretable meaning. This is because the main focus is usually placed on high-precision models that build large-span decision trees with many nodes and leaves or fuzzy systems with a large number of rules or very complex rule premises containing confusing AND connections. Interpretability improvement strategies -- either in a post-processing phase (e.g. after each incremental learning step) or directly applied in the learning stages (e.g. in the form of constraints in incremental and/or multi-objective optimization problems) --- are thus required. In this context, we may distinguish between [2]
- Linguistic interpretability and
- Visual interpretability
Linguistic interpretability deals with the semantics of fuzzy systems, for which terms such as readability and understandability of the models are essential to support rich interpretation of the models at a linguistic component-based level. Visual interpretability addresses the understandability of models at a visual level; that is, how they must be prepared, such that they or some of their components become intuitive and understandable when graphically shown to users/experts.
It is a matter of personal preference which type of interpretability an expert or operator favor. This means that an enriched MIC should include components supporting both types of interpretability preparation.
An essential step in guiding models towards a better-expressed interpretable power, is complexity reduction, especially the reduction of unnecessary complexities such as obsolete rules with low support, redundant fuzzy sets and overlapping local regions. Other important properties required at the linguistic level are rule-base consistency (no contradictory rules), distinguishability, local property, feature and rule importance levels, rule relevance, context descriptors, completeness, coverage, cointension as well as understandability of the input-output behavior.
An essential step in guiding models towards a better-expressed interpretable power, is complexity reduction, especially the reduction of unnecessary complexities such as obsolete rules with low support, redundant fuzzy sets and overlapping local regions. Other important properties required at the linguistic level are rule-base consistency (no contradictory rules), distinguishability, local property, feature and rule importance levels, rule relevance, context descriptors, completeness, coverage, cointension as well as understandability of the input-output behavior.
4.Human Feedback Integration Component (HFIC)
The primary goal of the HFIC is to provide methodologies that make rich human feedback understandable to and interpretable for the ML system: together with the MIC this should form a bi-directional homogeneous communication platform for humans and machines.
Once the MIC has prepared the models in an understandable form, thus enabling and stimulating experts, users and operators to contribute their knowledge to the model building process, the task of the HFIC component is to collect users input, and, ultimately to translate, interpret and integrate it into the machine learning models, such that learning from new incoming data can proceed smoothly. We may then speak of a combined data-driven and human-driven model evolution. Apart from good/bad rewards on model decisions, which are also provided in state-of-the-art EIS and active learning scenarios (see Section I.C), the HFIC should support two types of human input on a higher information level (which need not be mutually exclusive, but may even complement each other):
- Active manipulation of models or some of their components
- Passive sensation of emotional states or subconscious cognition
Within the context of active manipulation, experts may add or remove structural components (e.g. add a node considered important to a decision tree), move some decision boundaries or adjust some parameters (e.g. move the center of a rule considered incorrectly placed). Usually, experts will only be able to do this when they have fully understood and interpreted the model, see previous section. The key methodological requirement is to include these changes in the evolved models smoothly, dynamically and on-the-fly, such that the further update with new incoming data may continue with the manipulated models without compromising stability and process safety. In fact, adding structural components does not have a great effect on existing components, i.e. their parameters remain in the same converged state. However, moving decision boundaries, traversing sub-models or adjusting parameters may cause severe changes in existing model components, which is also the case when drifts occur in data streams --- see Figure 3 below.
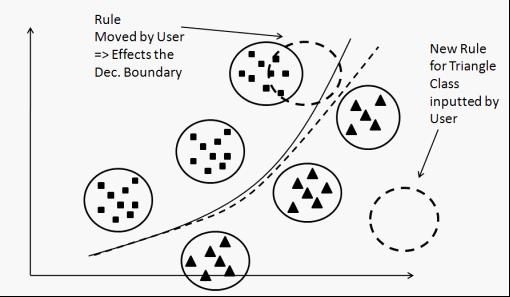
Figure 3: Cluster imputation and cluster manipulation by the user: the latter affects the decision boundary
In this context, an important question is how reliable the expert/operator input is, compared to the noise and uncertainty contained in the data from which the original model components were evolved. The reliability of the human input basically depends on two factors:
- The level of experience/skill of the operator/expert
- The emotional state and subconscious behavior of the operator/expert
The first aspect can be included by assigning experience levels to the persons working with the system and integrating these as weights when model components are manipulated. If the noise level or uncertainty of the data generation process is known, the data-driven model evolution phase may also include weights in the model building process. Depending on the certainty level, human input may be thus be down-weighted in relation to data input, or vice versa.
The same concept may be applied to factors influenced by emotional state or behavior. Here, the basic challenge is how to identify those states or even subconscious cognition, which requires a more profound analysis than explicitly assigning experience levels. One approach is to use vision and audio technology to deduce human emotion from facial expressions, voice or eye movements.
Eye tracking [49] and facial expression analysis [50] are potential methodologies for this purpose. Another line of research would be to analyze the EEG signals or fMRi images [51] [52], the psychological interpretation of which may point to boredom (due to lack of variety during work), fatigue (due to excessive working time), distraction (due to noise, disturbances), but also to positive perceptions (comfort, pleasure etc.). This interpretation may finally result in a translation of emotional states into levels of uncertainty or instability that are incorporated into the models as manipulation importance factors.
The framework of the HFIC combining these components is shown in Figure 4.
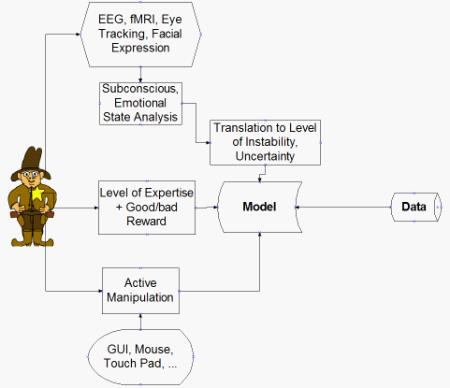
Figure 4: Components in the HFIC
Multi-modal interfaces interacting with the user via multiple senses are important to support active model manipulation by the user. These have also been used, for instance, in medical applications. The automobile industry is researching flexible protocols that change the way information is presented to a driver based on their perceived activity levels—for example, via heads-up displays, audible information and force-feedback to the steering wheel. Games-based tools employing multiple sensor devices have been used to elicit emotions, or to monitor, display, and thus so teach control of physiological signals such as pulse rates.
Conclusion
This purpose of this article was to present a new concept in the field of evolving intelligent systems, the so-called human-inspired evolving machines (HIEM), which allow a richer interaction and communication between humans and evolved models and offer the potential of deeper insights into the essential factors and key drivers in such interaction scenarios. Two components may play a central role: the model interpretation component (MIC) and the human knowledge integration component (HFIC). The former allows humans to understand models evolved from on-line measurement data streams, while the latter reverses this process by allowing direct manipulation of models and interpreting emotional states and subconscious responses. In an extended form an analysis of subconscious feedback may help to find out how people interact with ML systems and thus contribute to designing ML systems that prevent some negative perceptions/responses (such as fatigue or boredom). This approach may even have an impact on the design phases of model identification systems in general and may therefore be considered a fruitful line of future research.
Acknowledgment
This work was supported by the Austrian Science Fund (FWF, contract number I328-N23, acronym IREFS). It reflects only the author’s view. The author is grateful to Dr. Plamen Angelov for his invitation to write an article for the SMC newsletter.
References
| [1] | P. Angelov, D. Filev and N. Kasabov, Evolving Intelligent Systems --- Methodology and Applications. John Wiley & Sons, New York, 2010. |
| [2] | E. Lughofer, Evolving Fuzzy Systems --- Methodologies, Advanced Concepts and Applications. Springer, Berlin, 2011. |
| [3] | P. Angelov, Evolving Rule-Based Models: A Tool for Design of Flexible Adaptive Systems. Springer, Berlin, 2002. |
| [4] | N. Kasabov, Evolving Connectionist Systems: The Knowledge Engineering Approach - Second Edition.Springer, London, 2007. |
| [5] | S. Furao, T. Ogura and O. Hasegawa, “An Enhanced Self-organizing Incremental Neural Network for Online Unsupervised Learning”, Neural Networks vol. 20(8), pp. 893—903, 2007. |
| [6] | A. Abraham and Y. Dote, Engineering Hybrid Soft Computing Systems, Springer, New York, 2010. |
| [7] | J. Gama, Knowledge Discovery from Data Streams.Chapman & Hall CRC, Boca Raton, Florida, 2010. |
| [8] | P. Domingos and G. Hulten, “Mining high-speed data streams”, Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, 2010, pp. 71--80. |
| [9] | N. C. Oza and S. Russell, “Online bagging and boosting,” Artificial Intelligence and Statistics, pp. 105–112, 2001. |
| [10] | A. Bifet, G. Holmes, R. Kirkby and B. Pfahringer. “MOA: Massive Online Analysis”, Journal of Machine Learning Research, vol.11, pp. 1601—1604, 2010. |
| [11] | C.P. Diehl and G. Cauwenberghs, “SVM Incremental Learning, Adaptation and Optimization”, Proceedings of the International Joint Conference on Neural Networks Vol. 4, Boston, 2003, pp. 2685—2690. |
| [12] | D. Sannen, E. Lughofer and H. Van Brussel, „Towards Incremental Classifier Fusion”, Intelligent Data Analysis, vol. 14 (1), pp. 3—30, 2010. |
| [13] | L. Hartert, M.S. Mouchaweh and P. Billaudel, “A Semi-Supervised Dynamic Version of Fuzzy K-Nearest Neighbors to Monitor Evolving Systems”, Evolving Systems, vol. 1 (1), pp. 3—15, 2010. |
| [14] | P.P. Angelov, “An Approach for Fuzzy Rule-base Adaptation using On-line Clustering”, International Journal on Approximate Reasoning, vol. 35 (3), pp. 275--289, 2004. |
| [15] | E. Lughofer, “Extensions of Vector Quantization for Incremental Clustering”, Pattern Recognition, vol. 41 (3), pp. 995—1011, 2008. |
| [16] | D. Dovzan and I. Skrjanc, “Recursive Clustering based on a Gustafson-Kessel Algorithm”, Evolving Systems, vol. 2 (1), pp.15—24, 2011. |
| [17] | F. Farnstrom, J. Lewis and C. Elkan, “Scalability for Clustering Algorithms revisited”, SIGKDD Explorations, vol. 2 (1), pp. 51—57, 2000. |
| [18] | P. Hore, L.O. Hall and D.B. Goldgof, “Single Pass Fuzzy C Means”, Proceedings of the IEEE Fuzzy Systems Conference, FUZZ-IEEE, 2007. |
| [19] | O. Georgieva and S. Nedev, “Decision Support for Evolving Clustering”, in: Advances in Intelligent and Soft Computing, editors: C. Borgelt et. al., pp. 305—312, 2010. |
| [20] | W. Pedrycz, “A dynamic data granulation through adjustable clustering”, Pattern Recognition Letters, vol. 29 (16), pp. 2059–2066, 2008. |
| [21] | W. Pedrycz and P. Rai, “Collaborative clustering with the use of fuzzy c-means and its quantification”, Fuzzy Sets and Systems, vol. 159 (18), pp. 2399–2427, 2008. . |
| [22] | J. J. Rubio, “Stability Analysis for an Online Evolving Neuro-Fuzzy Recurrent Network”, editors: P. Angelov and D. Filev and N. Kasabov, Evolving Intelligent Systems: Methodology and Applications, John Wiley & Sons, New York, 2010, pp. 173--200. |
| [23] | J. J. Rubio, D. M. Vazquez, J. Pacheco, “Backpropagation to train an evolving radial basis function neural network”, Evolving Systems, Vol. 1 (3), pp. 173--180, 2010. |
| [24] | E. Lughofer, “Towards Robust Evolving Fuzzy Systems”, editors: P. Angelov and D. Filev and N. Kasabov, Evolving Intelligent Systems: Methodology and Applications, John Wiley & Sons, New York, 2010, pp. 87--126. |
| [25] | E. Lughofer , J. E. Smith, P. Caleb-Solly, M.A. Tahir, C. Eitzinger, D. Sannen and M. Nuttin, “On Human-Machine Interaction During On-Line Image Classifier Training”, IEEE Transactions on Systems, Man and Cybernetics, part A: Systems and Humans, vol. 39 (5), pp. 960--971, 2009. |
| [26] | D. Sculley, “Online Active Learning Methods for Fast Label-Efficient Spam Filtering”, Proceedings of the Conference on Email and Anti-Spam, 2007. |
| [27] | E. Lughofer, “On dynamic selection of the most informative samples in classification problems”, Proc. of the International Conference on Machine Learning and Applications (ICMLA) 2010, Washington DC, pp. 573-579. |
| [28] | A. Bouchachia, “An evolving classification cascade with self-learning”, Evolving Systems, vol. 1 (3), pp. 143—160, 2010. |
| [29] | J. A. Iglesias, P. Angelov, A. Ledezma, A. Sanchis, “Evolving classification of agent’s behaviors: a general approach”, Evolving Systems, Vol. 1 (3), pp. 161-172, 2010. |
| [30] | L. Pronzato. “Optimal experimental design and some related control problems”. Automatica, 44(2):303–325, 2008. |
| [31] | J.R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers, San Francisco, CA, 1993. |
| [32] | M. Humphrey, S. Cunningham and I. Witten. “Knowledge visualization techniques for machine learning”. Intelligent Data Analysis, vol. 2 (1–4), pp. 333—347, 1998. |
| [33] | P. Utgoff. “Incremental induction of decision trees”. Machine Learning, vol. 4(2), pp. 161–186, 1989. |
| [34] | J. Hühn and E. Hüllermeier, “FR3: A Fuzzy Rule Learner for Inducing Reliable Classifiers”, IEEE Transactions on Fuzzy Systems, vol. 17 (1), pp. 138--149, 2009. |
| [35] | A. Riid and E. Rüstern, “Identification of transparent, compact, accurate and reliable linguistic fuzzy models”, Information Sciences, vol. 181 (20), pp. 4378—4393, 2011. |
| [36] | R. Senge and E. Hüllermeier. “Pattern Trees for Regression and Fuzzy Systems Modeling”, Proc. of the IEEE World Congress on Computational Intelligence, Barcelona, Spain, 2010. |
| [37] | A. Lemos, W. Caminhas and F. Gomide. “Fuzzy Evolving Linear Regression Trees”, Evolving Systems, vol. 2 (1), pp. 1—14, 2011. |
| [38] | A. Shaker, R. Senge and E. Hüllermeier, “Evolving Fuzzy Patterns Trees for Binary Classification on Data Streams”, Information Sciences, in press, 2011. |
| [39] | D. Aha, Lazy Learning, Springer, Netherlands, 2009. |
| [40] | J. Casillas, O. Cordon, F. Herrera and L. Magdalena, Interpretability Issues in Fuzzy Modeling, Springer Verlag, Berlin Heidelberg, 2003. |
| [41] | M.J. Gacto, R. Alcala and F. Herrera, “Interpretability of Linguistic Fuzzy Rule-Based Systems: An Overview of Interpretability Measures”, Information Sciences, vol. 181 (20), pp. 4340—4360, 2011. |
| [42] | S.M. Zhou and J.Q. Gan, “Low-level interpretability and high-level interpretability: a unified view of data-driven interpretable fuzzy systems modeling”, Fuzzy Sets and Systems, vol. 159 (23), pp. 3091--3131, 2008. |
| [43] | L. Breiman, J. Friedman, C.J. Stone and R.A. Olshen, Classification and Regression Trees, Chapman and Hall, Boca Raton, 1993. |
| [44] | T. Barlow and P. Neville, “Case Study: Visualization for Decision Tree Analysis in Data Mining”, Proceedings of the IEEE Symposium on Information Visualization, 2001. |
| [45] | M. Humphrey, S. Jo Cunningham, I. H. Witten, “Knowledge Visualization Techniques for Machine Learning”, Intelligent Data Analysis, vol. 2, pp. 333—343, 1998. |
| [46] | P. Angelov and D. Filev, “Simpl_eTS: A Simplified Method for Learning Evolving Takagi-Sugeno Fuzzy Models”, Proceedings of FUZZ-IEEE 2005, Reno, Nevada, U.S.A., 2005, pp. 1068--1073. |
| [47] | J. V. Ramos, C. Pereira and A. Dourado, “The Building of Interpretable Systems in Real-time”, editors: P. Angelov and D. Filev and N. Kasabov, Evolving Intelligent Systems: Methodology and Applications, John Wiley & Sons, New York, 2010, pp. 127--150. |
| [48] | E. Lughofer, J.-L. Bouchot and A. Shaker, “On-line Elimination of Local Redundancies in Evolving Fuzzy Systems”, Evolving Systems, in press, 2011, DOI: 10.1007/s12530-011-9032-3. |
| [49] | A.T. Duchowski, Eye Tracking Methodology: Theory and Practice , Springer, London, 2009. |
| [50] | J. Ghent, Facial Expression Analysis: A Computational Model of Facial Expression, VDM Verlag Dr. Müller, 2011. |
| [51] | S. Sanei and J.A. Chambers, EEG Signal Processing, Blackwell Publishers, 2007. |
| [52] | S.A. Hüttel, A.W. Song and G. McCarthy, Functional Magnetic Resonance Imaging, Palgrave Macmillan, 2009. |
About the Author
 Edwin Lughofer received his PhD. degree from the Department of Knowledge-Based Mathematical Systems, University Linz,
where he is now employed as post-docoral fellow. From 2002-2010, he has participated in several international research
projects, such as the EU-projects DynaVis: www.dynavis.org, AMPA and Syntex (www.syntex.or.at). In this period, he has
published around 60 journal and conference papers in the fields of evolving fuzzy systems, machine learning and vision,
clustering, fault detection, image processing and human-machine interaction, including a monograph on ‘Evolving Fuzzy
Systems’ (Springer, Heidelberg). In these research fields he acts as a reviewer in peer-reviewed international journals
and as (co-)organizer of special sessions and issues at international conferences and journals. He is a member of the
editorial board and associate editor of the international Springer journal ‘Evolving Systems’.
Edwin Lughofer received his PhD. degree from the Department of Knowledge-Based Mathematical Systems, University Linz,
where he is now employed as post-docoral fellow. From 2002-2010, he has participated in several international research
projects, such as the EU-projects DynaVis: www.dynavis.org, AMPA and Syntex (www.syntex.or.at). In this period, he has
published around 60 journal and conference papers in the fields of evolving fuzzy systems, machine learning and vision,
clustering, fault detection, image processing and human-machine interaction, including a monograph on ‘Evolving Fuzzy
Systems’ (Springer, Heidelberg). In these research fields he acts as a reviewer in peer-reviewed international journals
and as (co-)organizer of special sessions and issues at international conferences and journals. He is a member of the
editorial board and associate editor of the international Springer journal ‘Evolving Systems’.
Research visits and stays include the following locations: Department of Mathematics and Computer Science (Philipps-Universität Marburg), Center for Bioimage Informatics and Department of Biological Sciences, Carnegie Mellon University, Pittsburgh (U.S.A.), Faculty for Informatics (ITI) at Otto-von-Guericke-Universität, Magdeburg (Germany), Department of Communications Systems InfoLab21 at Lancaster University (UK).
In 2006 he received the best paper award at the International Symposium on Evolving Fuzzy Systems, and in 2008 the award at the 3rd Genetic and Evolving Fuzzy Systems workshop. In 2007, he received a Royal Society Grant for know-how exchange with Lancaster University in the field of Evolving Fuzzy Systems. In 2010 he initiated the bilateral FWF/DFG Project ‘Interpretable and Reliable Evolving Fuzzy Systems’ and is currently key researcher in the national K-Project ‘Process Analytical Chemistry (PAC)’.